Recent searches
Search options


My team started looking at subgroup support for #WebGPU again. We pushed it out of the initial #WGSL feature set due to our staffing load and suspected non portability. Revisiting it now.
Sadly, and frustratingly, implementations don't do what programmers think should happen. We are seeing very very nonportable behavior.
Still collecting data across devices and platforms that we will share soon enough.
@dneto This is a major topic of my research.
Many vectorisation papers, including some from my uni, were written in a world without non-uniform intrinsic like that in mind.
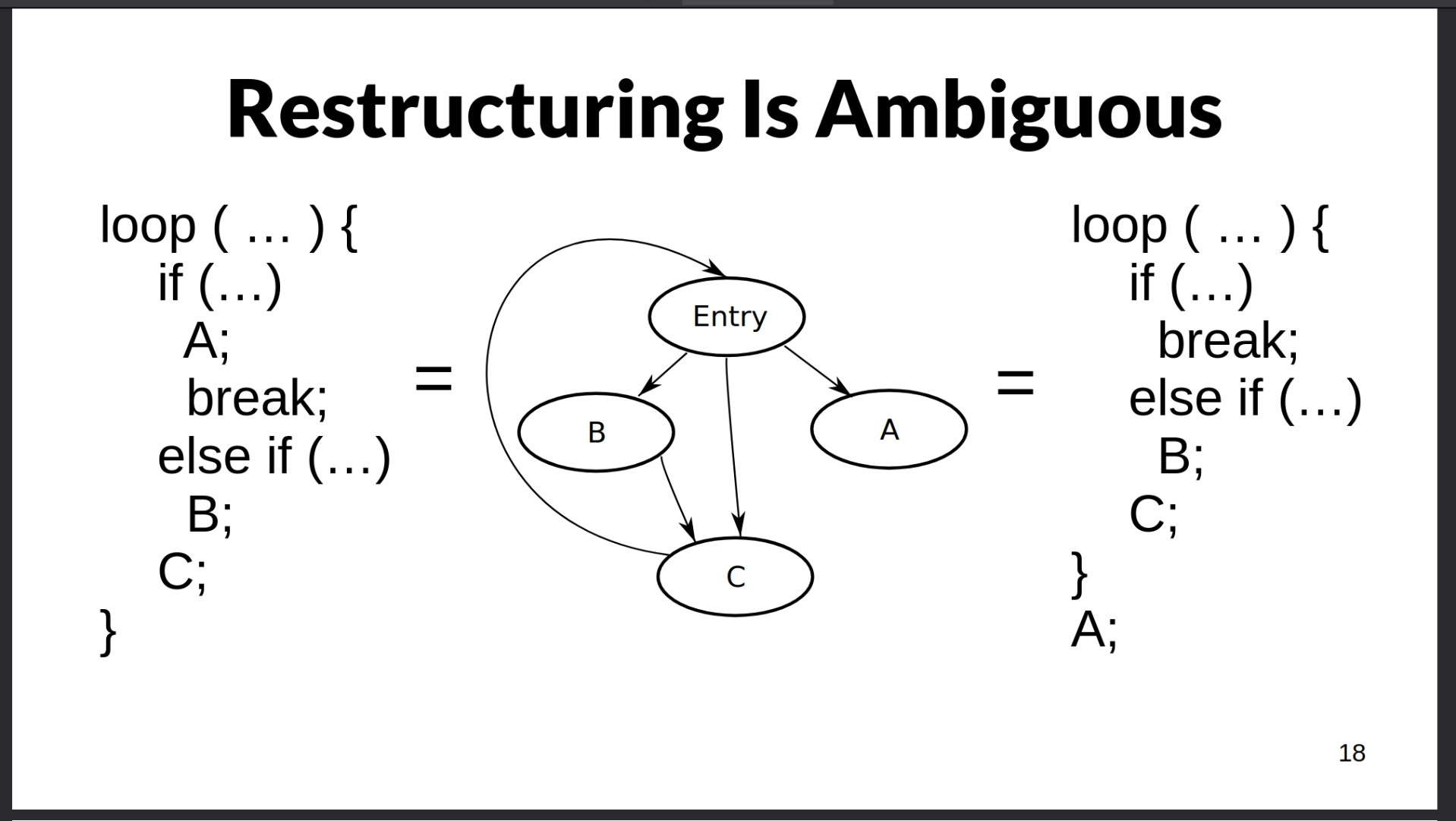
This led to using heuristics to make reconvergence decisions, often unstable under opts, which used to not matter semantically. Now it does!
The structured interpretation is the correct one, it's the one used by ISPC and others, and it's stable under optimisations, and programmers actually have the right intuition for it.
@dneto There are broadly two classes of implementations: LLVM-based shader compilers, which have arbitrary reconvergence behaviour, and NIR, which honors code structure throughout the pipeline.
LLVM and everything downstream from it, is facing a very tough challenge to address decades of development under scalar control-flow assumptions. I'm not sure it's fixable in a timely fashion
IRs that lack such information, like DXIL, are fundamentally flawed and need to be retrofit with structured info
@dneto If stable reconvergence semantics cannot be guaranteed, then non-uniform subgroup intrinsics are basically ill-defined nonsense.
Some people have argued that what threads participate to those should not be a correctness issue, that code should be written defensively.
To that I answer that if programmers are expected to respect uniformity guarantees by the API, then they must be given reliable tools to manipulate divergence and reconvergence.
@dneto If no reliable guarantees are provided, then non-uniform subgroup operations are conceptually a flawed idea and will only ever work on an ad-hoc basis in small programs with limited scopes.
And then I think they should just not be available at all, and the programming model should switch back to a purely scalar one, with SIMD execution being an implementation detail in sole control of the compiler.
@gob The SPIRV-Tools optimizer stack is another that always takes uniformity into account.
It's not the formalism that is decisive. It's possible to use an LLVM+based compiler safely. But only if you use transforms that don't degrade the reconvergence properties of the code. This requires extreme care and vigilance. But LLVM is a fast moving codebase and so doing so is very difficult. I think that's part of any so many GPU computers are longtime *forks*of LLVM.

@dneto The formalism is absolutely decisive, because it's the difference between something like NIR honoring structure "by construction", and something like LLVM requiring years (I think @nh et al have been working on this since at least 2019) to retrofit the concept in a way that works for the codebase at large.
At work we have an graph-based and implicitly IR called https://github.com/AnyDSL/thorin and it makes a ton of optimisations trivial, because the IR effectively normalises away a lot for us.
@gob @dneto To be fair, it's been very much an on again off again sort of project. And a lot of the delay has to do with LLVM community constraints, nothing inherent to the problem.
That said, I have come to the conclusion that a good compiler should be able to represent structured control flow constructs directly. It should be optional, but e.g. loop transforms on a free form CFG are kind of annoying.